
My colleagues have written some cool samples to work with AWS Lambda and API Gateway:
- running the Forge Viewer on top of Lambda and API Gateway: assume the model has been translated
- Transferring files with AWS Lambda among various web drivers and Autodesk storages: this is a 3legged workflow
- A Forge Viewer with Faster Serverless deployment using Claudia.js: assume the model has been translated
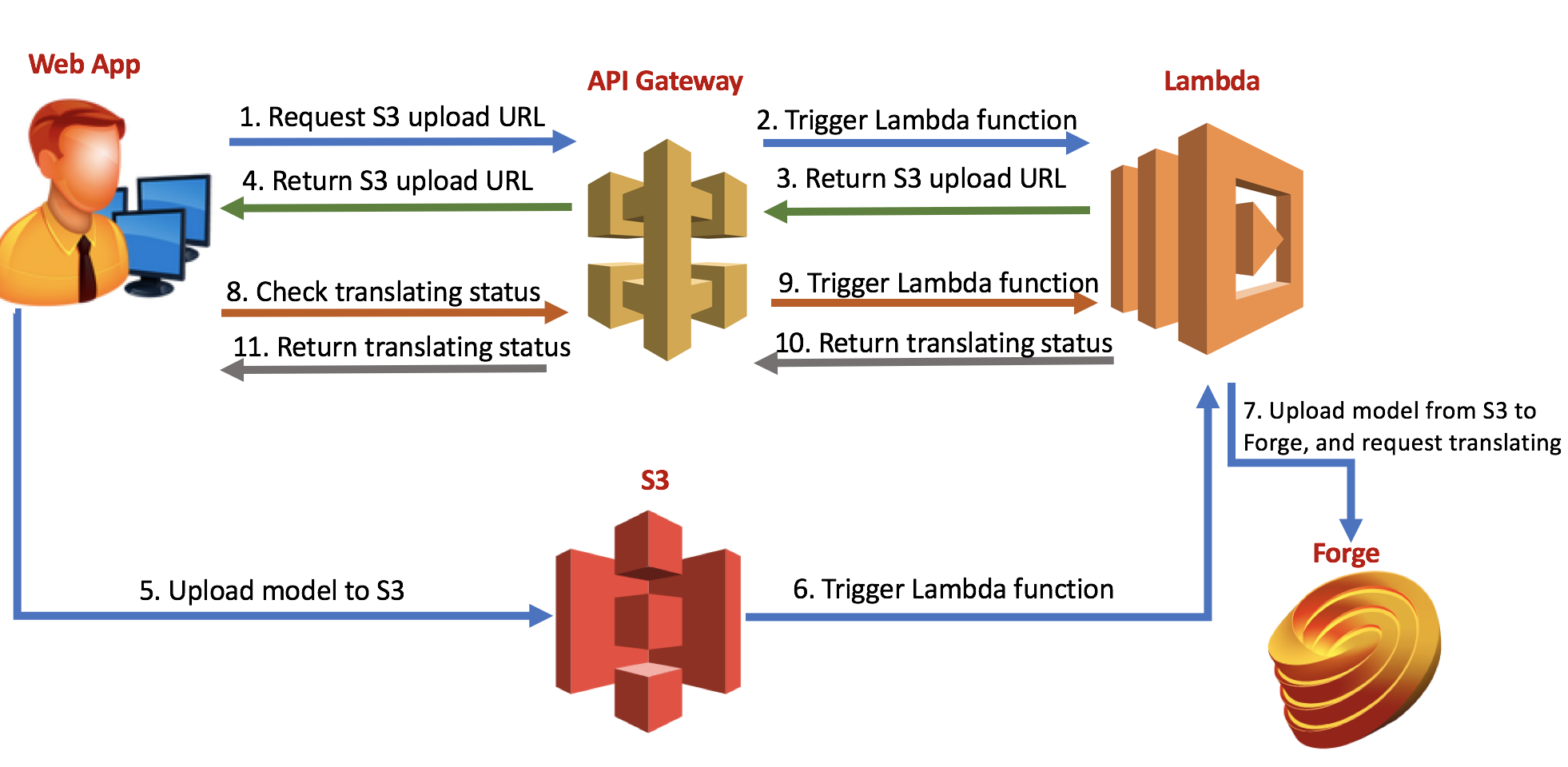
To supplement the whole workflow of 2legged, I practiced with related technologies. upload local file to Forge, request model translating, and check translating status. This is the logic:

- A Lambda function generates S3 signed uploading URL, sends back to client. The client uploads local file to S3.
- The uploading to S3 will trigger another Lambda function. This function downloads the file from S3 to the space of Lambda.
- Next, the Lambda codes invokes the process of Forge, upload file to Forge, and request translating.
- The last function of Lambda is to check the translating status, and return it to the client.
The complete project and test steps are available at: https://github.com/xiaodongliang/Forge-workflow-Lambda-APIGateway
In this article, I am sharing some key points regarding with #1 and #2 above.
At the beginning, I created an API Gateway with S3 proxy. I think it is more direct way to upload local file to S3. However, I hit strange issues (see this SO post) . In the same time, I got to know the limitation of payload of API Gateway (10M). That means, even if S3 proxy works, it does not either fit our requirement because the CAD file will much bigger than 10M in general. So I created the Gateway method binding with a Lambda function to generate the S3 signed uploading URL, by which, the client side can upload the file directly to S3.

And, I specified a S3 bucket to receive the uploading, and bind it with Lambda function.


Because I put all workflow in the same Lambda function, so I distinguished by the argument event of Lambda entry function. This is a code snippet from index.js:
// This is the entry-point to the Lambda function.
exports.handler = function (event, context,callback) {
console.log('event:' + JSON.stringify(event));
if (event.Records == null) {
if(event.query.uploadS3){
//if this is from trigger of API GateWay
//return the S3 signed url for uploading file
var s3Bucket = process.env.S3Bucket;
//the file name of this upload
var objectName = event.query.filename;
var s3 = new AWS.S3({
signatureVersion: 'v4',
});
//get upload url.
var url = s3.getSignedUrl('putObject', {
Bucket: s3Bucket,
Key: objectName,
Expires: 60*10, // increase the valid time if it is a large file
});
callback(null, url);
}
else if(event.query.checkForgeStatus){
//when checking the status of translating
var urn = event.query.urn;
checkForgeTransStatus(urn,callback);
}
else{
context.fail('Error', "unknown events!" + JSON.stringify(event));
return;
}
}
else{
//this should be the trigger from S3 events
// Process all records in the event asynchronously.
async.each(event.Records, processRecord, function (err) {
if (err) {
context.fail('Error', "One or more objects could not be copied.");
} else {
context.succeed();
}
});
}
};
After the client uploads the local file to S3, the Lambda function is trigged. Next, I used Forge SDK of Node.js to perform the subsequent calls. To maintain the style of Forge SDK, I did not dig into stream uploading directly (as Augusto mentioned in the blog Transferring files with AWS Lambda among various web drivers and Autodesk storages). Instead, the code will download the file to Lambda space firstly, and send to Forge. The below is the corresponding code snippet:
//get bucket name
var srcBucket = record.s3.bucket.name;
//get object name
var srcKey = decodeURIComponent(record.s3.object.key.replace(/\+/g, " "));
var s3 = createS3();
var getParams = {Bucket: srcBucket, Key: srcKey};
//writing the S3 object to Lambda local space
var wstream = require('fs').createWriteStream('/tmp/'+srcKey);
s3.getObject(getParams)
.on('error', function (err) {
console.log('s3.getObject error:' + err);
callback('s3.getObject error:' + err);
})
.on('httpData', function (chunk) {
//console.log('s3.getObject httpData');
wstream.write(chunk);
})
.on('httpDone', function () {
console.log('s3.getObject httpDone:');
console.log('sending to Forge translation');
wstream.end();
callForgeProcess('/tmp/'+srcKey,srcKey,callback);
})
.send(); In the next blog, I will continue to share some tips with #3 and #4 of the workflow.