
To implement a fast search we need to first index the data. It seems simple but involves 3 main steps: find the data, send it to the database and keep the data up to date. Forge allows us to find and collect metadata on CAD drawings, and to get notifications for new data, so we need a search database.
Elasticsearch
There are many ways to run Elasticsearch, which is a free, open-source software. But one of the easiest ways is to use it as a service on AWS. You can also run it under EC2 or on your own infrastructure. Here we will use the AWS service.
But how it works? With an AWS Account, go to Elasticsearch Service and create a new instance with all default settings, after a few minutes the instance should be ready to use. Make sure to apply the proper access policy, this sample uses access key & secret so you can connect locally (testing).
Data to search
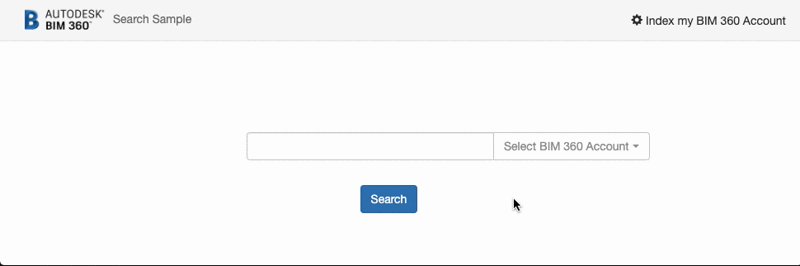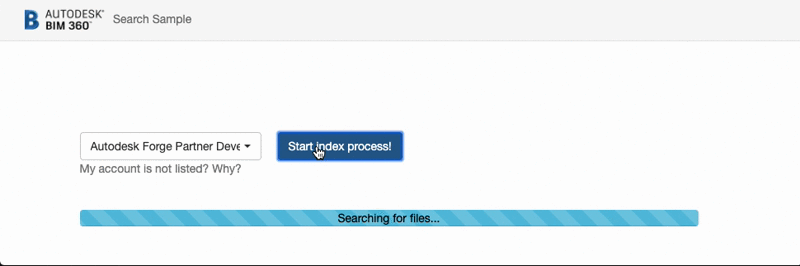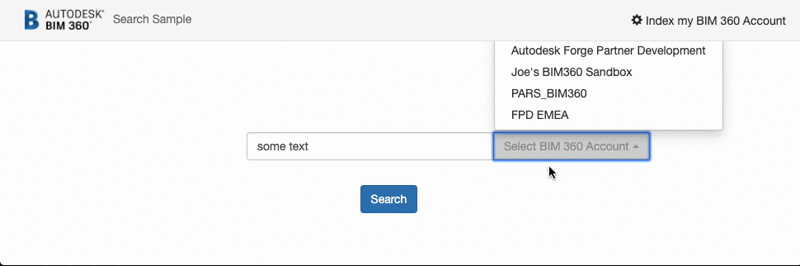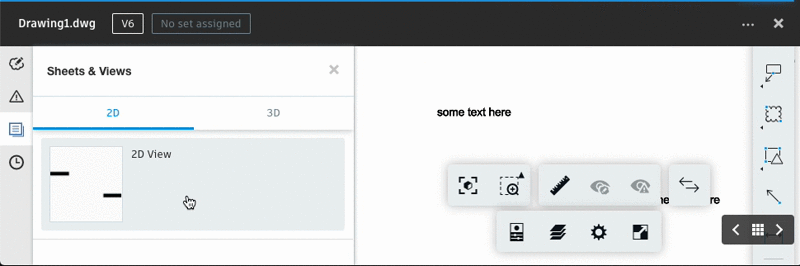
Forge allows us to access metadata of CAD files, but what king of data? Open a file, click on any element (or element of interest) and look at the property panel: that’s the data we can search on. And it should be useful for most use cases.
Using Model Derivative API an app can access the entire metadata of files. With this API, the data should come in the form of propertyName & propertyValue. This is super complete and descriptive, but can result in a lot of duplicated text as the property name will repeat for every element on the file.
Now the question is: do you want to search for a property name or for the property value? For a generic search, we don’t need all of that, we just need the property value, right? Of course, you may argue that you do need to search on the property name, which is totally fine and possible.
To conclude this section: as we don’t need the duplicated values and just need the property values, there is an undocumented way of accessing the Viewer property database. This was actually explored at this other article, and we’re using the objects_vals.json file for it.
Indexing
To index a large amount of data we need to break down the task. There are several reasons for it, but the two most important are: retry just the part that fails and avoid rate-limit errors.
Retry is important as several things can fail, from the data being inaccessible to connectivity problems. For this sample let’s break down the operation per folder (and per subfolder) and per file inside each folder. If any of those fails, we just retry that folder or file.
As we’re talking about long tasks we’re also talking about queuing, right? There are many ways to manage queues, including services from AWS or Azure. For this article sample, I’m using Hangfire, which is a .NET open-source library. Among other things, it allows us to manage how many jobs to run in parallel and retry in case of exceptions. Ultimately it helps manage rate-limit.
For this article and sample, let’s limit to the “Project Files” folder.
What about non-CAD files?
This indexing process should also work for non-CAD files, or file where the objects_vals.json is not available, like PDFs. To handle those formats, we would need to read them and extract the text, which is not part of this article and sample.
Format the data
As we want to search on BIM 360 Document Manager files we need to be able to link back to those files. When we open a file on BIM 360 UI we can see the URL of a given files:
https://docs.b360.autodesk.com/projects/{projectId}/folders/{folderUrn}/detail/viewer/items/{itemUrn}
When showing the search results, we also need the versionUrn to get the thumbnail and fileName to display.
Finally, as Elasticsearch store documents, we need to define our documentId, so let’s use the itemUrn, which is the same for all versions of that file. This leads us to only store the last version of a file, meaning our search will only find hits on the last version.
Keeping the data up to date
The indexing process takes a lot of time and resources. And we don’t need to index all files more than one time, just need the new files (or versions), right? So let’s use Webhooks to notify our app of any new file or version, get its metadata and update the respective document on Elasticsearch.
During the indexing process let’s add a webhook for dm.version.added on the “Project Files” level, which should capture new files on any subfolder.
Note that the webhook callback can happen any time and we will need a valid access token to access the file metadata.
Managing access & refresh tokens
The entire indexing operations and later updates (via Webhooks) require a 3 legged token. We need to keep a database with the current access token, when it expires, the respective refresh token and when it expires. On every Forge access to Data Management, let’s look at the access token, use it if still valid, if not use the refresh token to get a new one and store the new refresh token. For that we’ll use a MongoDB database where a documentId is the Autodesk UserId that started the indexing process.
About the code
The .NET Core C# code for this sample is divided into some key files:
- DataManagementCrawlerController: starting from the Account/Hub level, look at every project and folder. For each file found it queues up a Model Derivative job
- ModelDerivativeController: get the file metadata and send it to Elasticsearch.
- OAuthController & OAuthDatabase: manage access & refresh token in session and in database
- Webhook & WebhookController: register the hooks and receive the callbacks
Seach is a big and deep topic, this is just a first look at it. I hope you find this sample useful to get started.